This blog post will focus on creating the S3 bucket, uploading a file and downloading a file from the S3 bucket.
AWS SDK for Python (Boto3) makes it easy to integrate your Python application to create, configure, and manage AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3) , Amazon DynamoDB and more.
The main objective of Boto3 was to make it simpler for the programmers to write python code that interacts with Amazon web services.
To access the AWS resources from python program we need to install AWS Command Line Interface.To setup AWS CLI in the remote desktop follow install the AWS Command Line Interface (CLI) section in the below link:
Use the Python SDK to Access Cloud Storage – AWS
Create a project and install python SDK:
Login into your Remote Desktop using Bitvise SSH client. Open the terminal and create a new VS Code project as follows:
cd ~
mkdir pycloud
cd pycloud
code .Open a terminal window and install the boto3 package:
pip install boto3After installing SDK package, select python interpreter for your virtual environment as follows:
- press Ctrl-Shift-P. Then begin typing Python: Select and click to select the Python Interpreter
- List of interpreter choices will be displayed.Select the virtual environment that we just created.
Setting up the credentials using AWS configure:
You need to setup your credentials to authenticate python program. You can setup the credentials using the access key that you created using IAM(Identity Access Management) service. You can create a new one using the following instructions:
1. Navigate to IAM console.
2. On the navigation pane, choose ‘Users’ and select (desired) IAM user.
3. On Security credentials tab => click create access key button.
A new window will appear that new access key is created and then you can either copy the access key Id and secret access key or download the .csv file. The secret access key can be viewed only one time, you cannot recover later. You can create a new access key at any time, but you can create only 2 access keys for each user. If you open .csv file with Excel, here is how the access Key Id and secret access key look like:

Once you have the access key ID and secret access key use the ‘aws configure’ command to configure Aws credentials.
aws configureAt the prompts,
- Paste Access key Id
- Paste the secret access key
- Enter default region – you can enter ‘us-east-2’ as most of your resources are in ohio
- Default output format for AWS CLI command outputs-there are several choices ,but choose JSON
When the aws configure command is complete, your credentials are stored in 2 files in the VM’s file system. The AWS CLI stores sensitive credential information that you specify with aws configure in a local file named credentials, in a folder named .aws in your home directory. The less sensitive configuration options that you specify with aws configure are stored in a local file named config, also stored in the .aws folder in your home directory.
Python program to create new S3 Bucket:
To create s3 Bucket using python following are the requirements:
1.ACL(Access Control List): ACLs enables to manage access to the buckets and objects.Each bucket and object has an ACL attached to it as a sub resource. It defines which AWS accounts or groups are granted access and the type of access.The set of permissions that Amazon S3 supports in an ACL are here.
2.Bucket:Amazon S3 supports global buckets, which means that each bucket name must be unique across all AWS accounts in all the AWS Regions within a partition.
3. Location Constraint: This is optional. If you want to create a bucket with in a specific region namely ‘us-east-2’ you need specify the region name within the location constraint. If you don’t specify a particular region then the AWS region in which your bucket will be stored will be “us-east-1” which is the nearest data center to be accessible with less latency.
The below code creates an s3 Bucket in the us-east-2 region and only objects are publicly accessible.
import boto3
s3_client=boto3.client('s3')
response=s3_client.create_bucket(
ACL='private',
Bucket='jayanannapa2-s3-bucket-1'
CreateBucketConfiguration={
'LocationConstraint':'us-east-2'
},
)
print("successfully created s3 Bucket")
Start Debugging to run the program. The output of the python program is as follows:
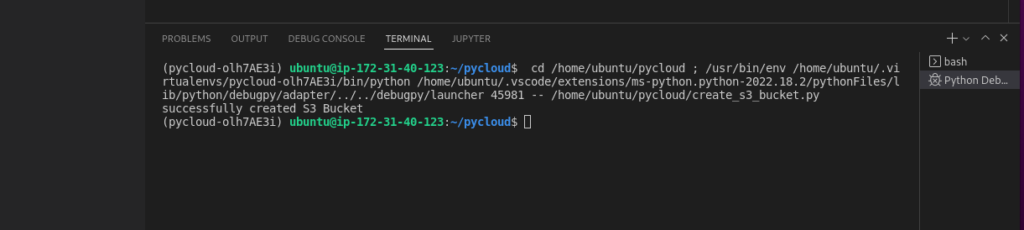
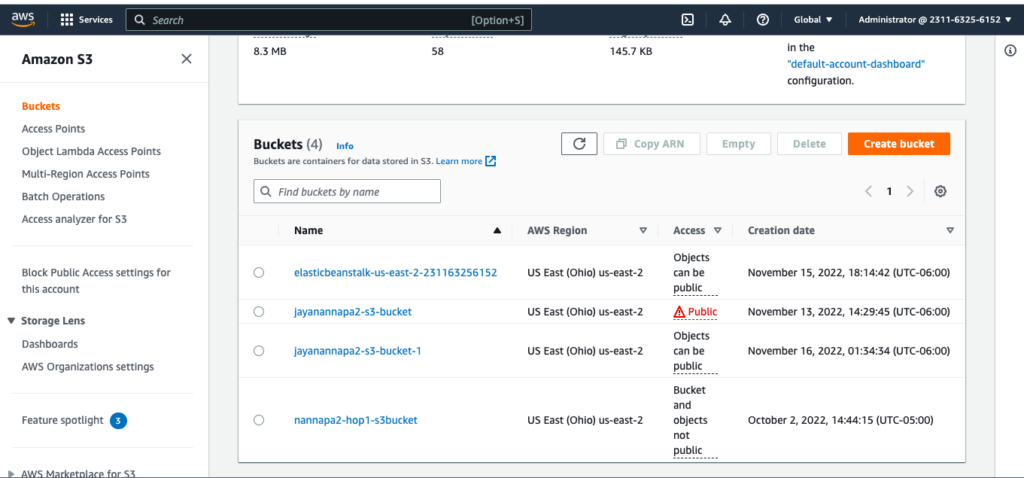
You can see that the S3 bucket we created using the Python SDK is visible from the AWS console.
Python program to list all the Buckets
The below python program defines a function(“list_buckets()”) that obtains S3_client and uses this obtained client to list all the buckets that the user has access to and print the bucket names.
By looking at this code, the response object and its pieces are seem to be accessed as if response is a dictionary with other dictionaries inside of it.
import boto3
def list_buckets():
s3_client = boto3.client('s3')
response = s3_client.list_buckets()
print("These are buckets accessible by your credentials")
for bucket in response["Buckets"]:
print(f' {bucket["Name"]}')
list_buckets()
Start Debugging to run the program. The output of the python program is as follows:
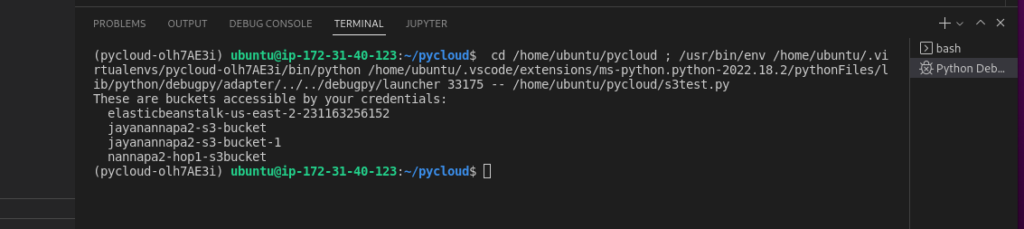
Python program to upload a file into S3 bucket:
The AWS SDK for Python provides a pair of methods to upload a file to an S3 bucket.
In the below code first we create a s3 client. Then we use the upload_file() method to upload a file into s3 bucket.
The upload_file() method accepts a file name, a bucket name, and curr_path.
- bucket name: The name of the bucket to which file needs to be uploaded
- curr_path: path of the file where it is located in the local system which we need to upload into s3 bucket
- file_name: S3 object name, is a new filename with which we need to store the object/file into the s3 bucket or you can leave it as it is.
import boto3
s3_client = boto3.client('s3')
bucket='jayanannapa2-s3-bucket-1'
curr_path=/home/ubuntu/Downloads/cake.jpg
file_name=cake.jpg
response=s3_client.upload_file(bucket,curr_path,file_name)
print("Successfully uploaded a file into S3 bucket")
Start Debugging or select Run to run the program. The output of the python program is as follows:
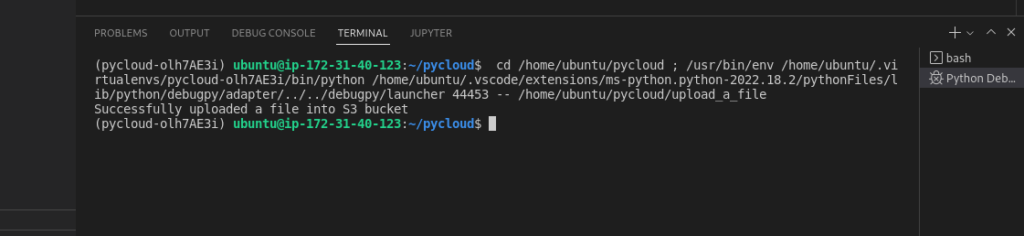
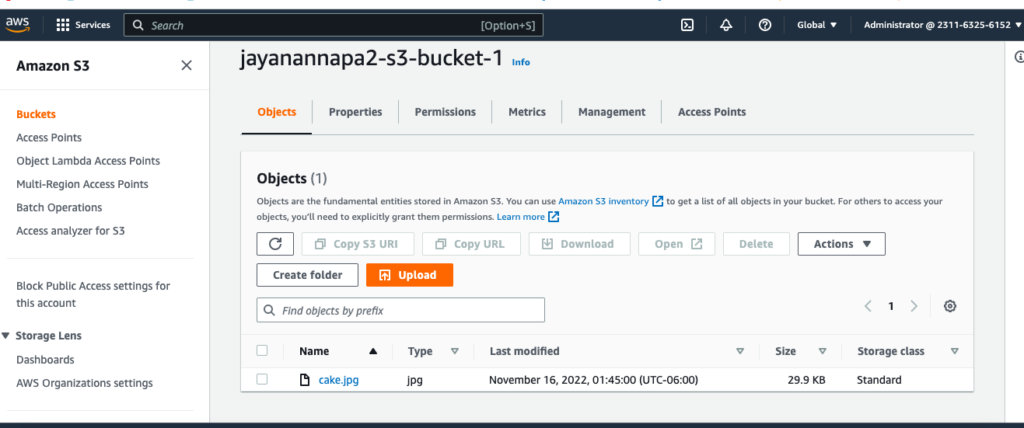
You can see that the object is uploaded into S3 bucket using the Python SDK is visible from the AWS console.
Python program to download a file from S3 bucket:
The below python program is used to download a file from s3 bucket to local system. Here at first we create a s3 client and then get the bucket-name from which we need to download the object from.The Key column in the download_file() method is used to specify the file that needs to be downloaded and Filename specifies the path where the file wants to be downloaded in the local file system and we can specify the new name to the file here.
import boto3
s3_client = boto3.client('s3')
bucket=s3_client.Bucket('jayanannapa2-s3-bucket-1')
print('Downloading file from s3...')
bucket.download_file(Key='cake.jpg',Filename='/home/ubuntu/Downloads/cake_copied.jpg')
Start Debugging to run the program. The output of the python program is as follows:
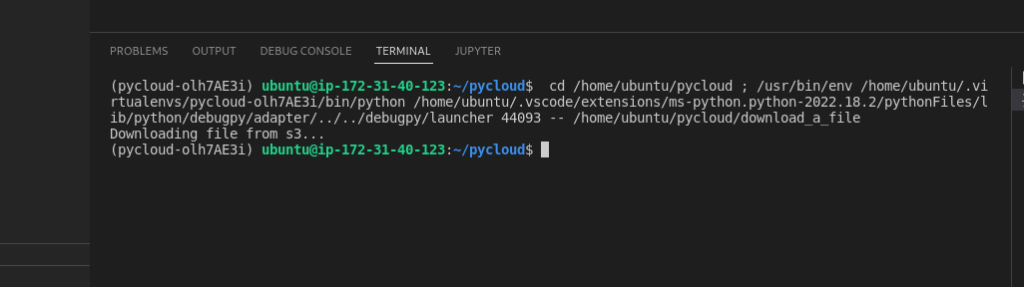
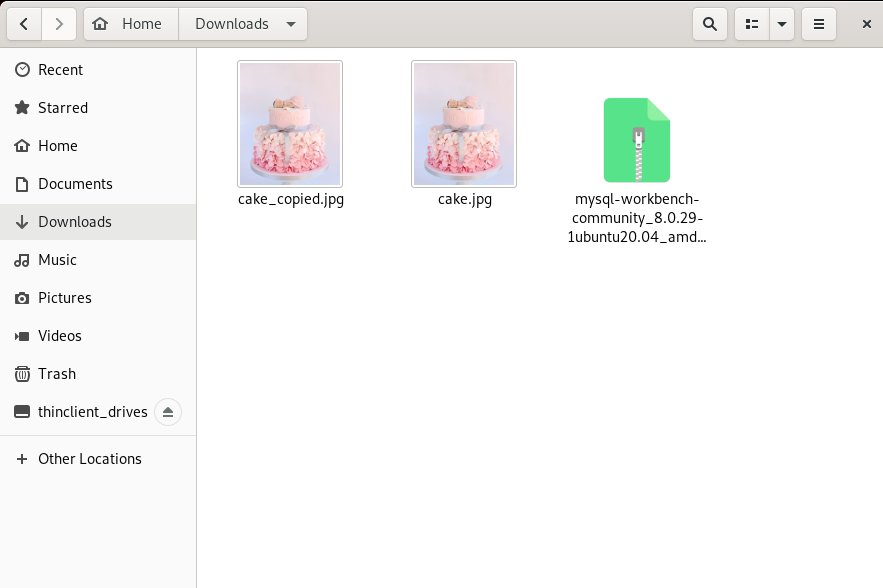
Now you can see the image named “cake.jpg” is downloaded as “cake_copied.jpg” in the Downloads folder of the local file system.
Here in this blog we can able to see provisioning and managing s3 buckets using python boto3 library. In this article we have covered some of the basic operations performed on the AWS S3 buckets to upload a file ,download a file and creation of the bucket using python SDK’s. Everyone can provision and perform various operations on different AWS services with minimal python knowledge.